A routine system cleanup at Buffer, the social media management platform, recently led to the unexpected discovery of seven background processes and workers that had been running silently and uselessly for up to five years. This significant finding, detailed by the company, underscores the pervasive challenge of technical debt and the critical importance of diligent infrastructure lifecycle management in complex, long-lived software systems. The revelation not only highlighted financial inefficiencies but, more importantly, exposed the substantial hidden costs associated with cognitive load, delayed onboarding, and unnecessary maintenance burden on engineering teams.
The initial project, seemingly modest in scope, aimed to streamline internal system communications, specifically focusing on Amazon Simple Queue Service (SQS) queues. SQS acts as a crucial intermediary in distributed systems, allowing different parts of a system to communicate asynchronously. One component can deposit a "message" or task into a queue, and another component can retrieve and process it later, without direct, real-time interaction. This "waiting room" analogy for tasks is fundamental to scalable, resilient architectures. Buffer’s maintenance initiative focused on updating local testing tools for these queues and rationalizing their configurations. However, as engineers meticulously mapped out the active queues and their associated consumers and producers, they stumbled upon the digital equivalent of forgotten relics: background processes, often implemented as cron jobs (scheduled tasks), that were consuming resources and attention without contributing any value.
The Pervasive Cost of Digital Drift: Beyond Monetary Figures
While the immediate financial implications of these dormant processes were calculable, Buffer’s analysis quickly demonstrated that monetary waste, though real, represented only a fraction of the total cost. A quick estimation suggested that one such worker alone could have cost the company between $360 and $600 over its five-year lifespan. Extrapolating this across the seven identified processes, the total financial drain could range from approximately $2,500 to $4,200 over five years. While this sum might be considered modest for a company of Buffer’s scale, it represents pure, unadulterated waste – resources that could have been reinvested or saved.
However, Buffer engineers emphasized that the true impact transcended these direct financial outlays. The human and operational costs proved far more significant. Every time a new engineer joined the team, they would encounter these enigmatic processes during their onboarding. Questions like, "What does this worker do?" or "Is this critical?" would inevitably arise, consuming valuable time as new hires and experienced team members alike struggled to decipher the purpose of code paths that had long since become obsolete. This uncertainty fostered a culture of hesitancy, where engineers might be reluctant to modify or remove code for fear of unknowingly disrupting a critical, albeit poorly understood, function. This "fear of touching" is a common symptom of high technical debt and institutional knowledge silos.
Moreover, even dormant infrastructure demands attention. Security vulnerabilities, outdated dependencies, or compatibility issues stemming from wider system changes would occasionally necessitate maintenance cycles. Engineering teams found themselves dedicating precious time and effort to update, patch, or simply investigate code that served no functional purpose. This diversion of resources from active development or truly essential maintenance represents a significant opportunity cost, slowing innovation and increasing operational overhead. Over time, the institutional memory surrounding these processes inevitably faded. The original context – whether a temporary fix, a one-time migration, or a feature that was later deprecated – was lost as engineers moved on from the company, leaving behind a legacy of unexplained code.
The Genesis of Obsolete Infrastructure: A Natural Phenomenon
The existence of such "zombie infrastructure" is not an isolated incident but a common challenge in the lifecycle of any mature, evolving software system. Buffer’s experience highlights that these aren’t typically the result of individual negligence but rather a systemic failure in process. Several common scenarios contribute to this digital entropy:
- Feature Deprecation: A product feature is retired, but the background jobs or scheduled tasks designed to support it continue to run, unnoticed.
- Temporary Solutions Becoming Permanent: A worker is spun up as a "temporary" measure for a data migration or a critical bug fix, but the decommissioning step is overlooked once its immediate purpose is served.
- Architectural Shifts: Major system overhauls or refactors can render existing scheduled tasks redundant. If a component is replaced or its functionality absorbed elsewhere, the old task might persist without a clear flag for removal.
Buffer cited a specific example: for years, the company sent birthday celebration emails to customers. This involved a scheduled task that systematically scanned the entire database for matching birthdays and dispatched personalized emails. In 2020, a significant refactor involved switching the transactional email tool. While the new system handled email delivery, the original birthday worker was never decommissioned. It continued to run for another five years, meticulously checking for birthdays and attempting to send emails through a no-longer-used system, consuming resources to achieve absolutely nothing. This incident perfectly encapsulates how "failures of process," rather than individual errors, allow such issues to fester. Without intentional cleanup mechanisms integrated into the development lifecycle, systems naturally accrue cruft.
Architectural Evolution as an Unforeseen Catalyst for Discovery
Paradoxically, Buffer’s ability to uncover these long-lost processes was significantly aided by a prior architectural decision that wasn’t initially intended for this purpose. Like many technology companies, Buffer had embraced the microservices paradigm years ago. This approach advocates for splitting a monolithic application into numerous smaller, independent services, each with its own codebase, deployment pipeline, and infrastructure. The rationale was clear: independent deployments, clear team boundaries, and enhanced scalability.

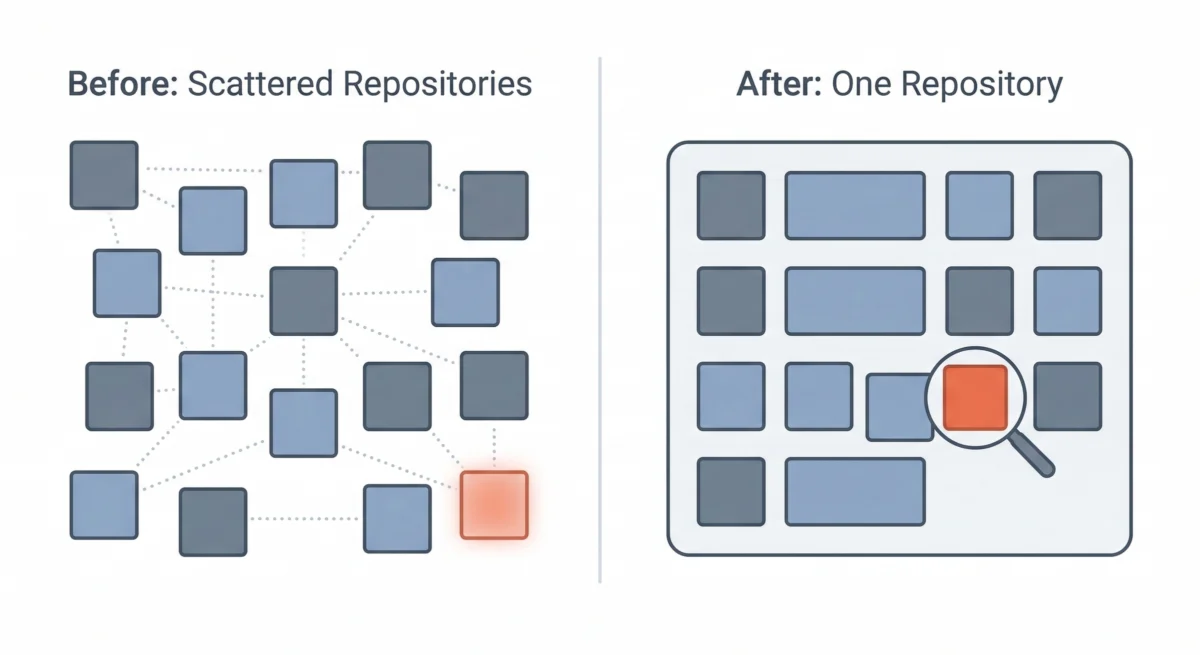
However, over time, Buffer found that the overhead of managing dozens of separate repositories for a team of its size began to outweigh the benefits. The cognitive load of navigating disparate codebases, managing numerous deployment configurations, and ensuring consistent tooling across a fragmented landscape became a bottleneck. Consequently, Buffer embarked on a strategic consolidation, transitioning to a multi-service single repository, often referred to as a "monorepo." While the logical boundaries between services remained, their codebases were brought together under one unified roof.
This architectural shift proved instrumental in the discovery of the dormant infrastructure. In the fragmented microservices environment, each repository acts as an isolated "island." A forgotten worker in one service’s repository might never register on the radar of engineers working in another. There was no single, comprehensive view of all active queues, no unified search mechanism to trace producers and consumers across the entire system. The monorepo, however, changed this dynamic fundamentally. With all code residing in a single repository, engineers gained a holistic perspective. They could systematically trace every SQS queue, identify its producers (components sending messages) and consumers (components processing messages). This unified view made it possible to spot critical anomalies: queues with producers but no active consumers, or workers referencing queues that no longer existed. The consolidation, though not designed to specifically identify zombie infrastructure, created the necessary transparency and interconnectedness that made such discoveries almost inevitable.
Systematic Remediation: Tracing, Verifying, and Documenting
Once the orphaned processes were identified, Buffer adopted a methodical approach to their remediation, emphasizing caution and thoroughness:
- Tracing Origins: The first step involved a deep dive into the history of each process. Engineers meticulously sifted through git commit histories, old documentation, and internal communication logs to reconstruct the original purpose and context behind each worker’s creation. In most cases, the initial rationale became clear: a one-time data migration, a feature that was subsequently sunset, or a temporary workaround that had simply outlived its necessity.
- Confirmation of Disuse: Before any process was permanently removed, Buffer implemented a critical verification step. Logging was added to each identified worker to monitor its activity over several days. This allowed engineers to confirm definitively that these processes were indeed dormant and not, as feared, quietly performing some obscure but vital function that had been overlooked. This cautious approach minimized the risk of unintended side effects during the cleanup.
- Incremental Removal: Rather than a sweeping deletion, Buffer opted for an incremental removal strategy. Processes were decommissioned one by one, allowing the team to closely monitor for any unexpected system behavior or regressions. Fortunately, no adverse side effects were observed, reinforcing the initial assessment of their redundancy.
- Comprehensive Documentation: A crucial part of the cleanup involved documenting the findings. Detailed notes were added to Buffer’s internal knowledge base, outlining what each process had originally done, why it was created, and the rationale for its removal. This ensures that future engineers will not encounter these ghost processes or wonder about the disappearance of critical system components, preserving valuable institutional knowledge.
The Post-Cleanup Landscape: Clarity, Efficiency, and Confidence
While the full, long-term impact of this cleanup is still being measured, Buffer has already observed tangible benefits. The company’s infrastructure inventory is now significantly more accurate and reliable. When internal stakeholders or new team members inquire about the active worker processes, engineers can respond with confidence, providing a clear and precise overview of the operational landscape.
Furthermore, the onboarding experience for new engineers has demonstrably improved. The removal of mysterious, non-functional processes has streamlined the learning curve, allowing new hires to focus on understanding the truly active and relevant components of Buffer’s system. The codebase now more accurately reflects the company’s current operations, rather than a historical archive of past initiatives. This reduction in cognitive load and ambiguity fosters a more productive and confident engineering environment.
Archaeology and Prevention: A New Paradigm for Refactoring
Buffer’s experience has profoundly reshaped its approach to system maintenance and refactoring. The biggest takeaway is the recognition that every significant refactoring effort presents a unique opportunity for "archaeology." When engineers are deeply immersed in understanding the intricate connections within a system, they are in the ideal position to critically question the necessity of every component. That old queue, the worker for a forgotten data migration, the scheduled task referencing an obsolete feature – these are precisely the relics that can be unearthed during such deep dives.
Moving forward, Buffer is integrating specific preventative measures and archaeological practices into its engineering processes:
- Mandatory Decommissioning Protocols: Implementing formal procedures for retiring features and infrastructure, ensuring that all associated background jobs, queues, and configurations are systematically removed or updated.
- Regular Infrastructure Audits: Scheduling periodic, dedicated audits of background processes and queues to proactively identify dormant or underutilized components, similar to a digital inventory check.
- Enhanced Code Ownership and Lifecycle Management: Clarifying ownership for different parts of the system and emphasizing the full lifecycle of components, from creation to eventual decommissioning.
- Documentation Standards: Reinforcing the importance of clear, up-to-date documentation for all background processes, including their purpose, dependencies, and expected lifespan.
- Leveraging Architectural Advantage: Continuing to capitalize on the transparency afforded by the multi-service single repository to maintain a unified view of all running components.
Buffer still has older segments of its codebase that are yet to be migrated to the single repository. As this consolidation continues, the company anticipates uncovering more of these hidden relics. However, the foundational processes and architectural setup are now in place to not only identify existing dormant infrastructure but also to significantly prevent the formation of new instances. The overarching lesson is clear: in a unified code environment, orphaned infrastructure has nowhere to hide, paving the way for more efficient, transparent, and manageable software systems.