Buffer, the social media management platform, recently disclosed the discovery of seven long-dormant background processes, colloquially termed "zombie" infrastructure, that had been silently operating within its systems for up to five years without performing any useful function. This significant revelation came to light during a routine internal project aimed at streamlining system communications and performing maintenance on the company’s Amazon Simple Queue Service (SQS) queues. The findings offer a compelling case study on the insidious accumulation of technical debt and the critical importance of proactive system hygiene in modern software development.
The initiative commenced as a seemingly straightforward undertaking: an effort to refine how various parts of Buffer’s intricate systems communicate asynchronously. At the heart of this communication strategy is SQS, Amazon’s fully managed message queuing service. SQS queues function as vital intermediary "waiting rooms" for tasks, allowing different components of a distributed system to exchange messages without direct, real-time interaction. One system might "drop off" a message detailing a task, and another can "pick it up" later, ensuring decoupling and resilience. This mechanism is crucial for operations like processing user data, sending notifications, or handling scheduled tasks without requiring the sending system to await an immediate response. The initial scope of Buffer’s project involved updating local testing tools for these queues and rationalizing their configuration to enhance efficiency and reliability.
However, as engineers meticulously mapped out the active SQS queues and their associated consumers and producers, they encountered an unexpected anomaly. Their comprehensive audit revealed multiple background processes, including both continuously running workers and scheduled cron jobs, that were referencing queues or performing operations devoid of current purpose. A total of seven distinct entities were identified, some of which had been executing automatically for half a decade, consuming resources and contributing to system complexity without any beneficial output. This silent operation underscored a profound challenge inherent in evolving software architectures: the tendency for forgotten or deprecated components to persist long after their utility has expired.
The Multifaceted Costs of Neglected Systems
While the immediate financial implications of these "zombie" processes might appear modest at first glance, the broader impact extends far beyond mere monetary waste. A quick calculation by Buffer engineers estimated that a single such worker could have incurred costs ranging from $360 to $600 over a five-year period. Multiplied across seven processes, and considering the potential for even larger instances in more complex enterprises, these sums quickly escalate into substantial, avoidable expenditures. In the realm of cloud computing, every running instance, every compute cycle, every unit of storage, and every network egress point contributes to an organization’s operational bill. Maintaining infrastructure that serves no purpose is, by definition, pure waste.
However, industry experts and Buffer’s own internal analysis suggest that the financial cost is often the smallest part of the problem. The hidden costs, often referred to as technical debt, are far more insidious and damaging:
- Operational Burden and Cognitive Load: Every time a new engineer joins the team or an existing one attempts to understand a system, these mysterious processes become a roadblock. Questions like "What does this worker do?" or "Is this queue still active?" consume valuable onboarding time and introduce uncertainty. Engineers become hesitant to modify or remove code paths, fearing that a seemingly innocuous component might be critical, even if its purpose is unclear. This "fear of touching" stifles innovation and slows development cycles.
- Maintenance Overhead: "Forgotten" infrastructure rarely remains entirely untouched. It still requires periodic attention: security updates for underlying operating systems or libraries, dependency bumps to maintain compatibility with other parts of the system, and compatibility fixes when external services or APIs change. This diverts valuable engineering resources towards maintaining code that provides zero business value, effectively siphoning effort away from product development or genuine system improvements.
- Erosion of Institutional Knowledge: Over time, the original context and rationale behind such processes fade. The engineers who created them may have left the company years ago, taking with them the critical institutional knowledge. Without clear documentation or an evident purpose, determining if a component is truly obsolete becomes an arduous, often impossible, task. This knowledge vacuum contributes significantly to technical debt and increases the risk of accidental breakage during future system modifications.
- Potential Security Vulnerabilities: Unmaintained or forgotten code paths, especially those with network access or data processing capabilities, can represent latent security risks. If not regularly patched and updated, they can become entry points for malicious actors, undermining the overall security posture of the system.
The Inevitable March of System Entropy: How "Zombie" Processes Emerge
The presence of these defunct processes is not typically a result of individual oversight but rather a natural consequence of system evolution and a lack of intentional, systemic cleanup mechanisms. As Buffer engineers noted, this phenomenon is common in any long-lived software system where features are added, deprecated, and architectural patterns shift.
Several common scenarios contribute to the rise of "zombie" infrastructure:
- Feature Deprecation: A feature might be retired or replaced, but the background jobs or scheduled tasks designed to support it are not consequently removed. They continue to run, endlessly performing operations that no longer serve a purpose.
- Temporary Solutions Becoming Permanent: Engineers often spin up "temporary" workers or scripts to handle one-time data migrations, urgent fixes, or experimental features. Without a strict decommissioning process, these temporary solutions can easily be forgotten and left running indefinitely.
- Architectural Shifts: Major architectural changes, such as migrating to a new service provider or refactoring core functionalities, can render older processes redundant. If the migration plan does not explicitly include the removal of superseded components, they can persist unnoticed.
Buffer experienced a classic example of this with its former birthday celebration email system. Historically, the company ran a scheduled task that would scan its entire customer database daily for birthdays matching the current date and dispatch personalized emails. In 2020, as part of a broader refactor, Buffer switched to a new transactional email tool. While the new tool handled the email sending, the original scheduled task, responsible for identifying the birthdays and initiating the send, was inadvertently overlooked. It continued to execute silently for five more years, performing its database scan and attempting to trigger an email send through a now-defunct or redirected pathway. This particular incident highlights how a seemingly minor oversight during a larger transition can lead to years of unnecessary operational burden.
Such occurrences are often framed not as failures of individual engineers, but as systemic failures of process. Without robust, intentional cleanup protocols integrated into the software development lifecycle, systems are inherently prone to accumulating entropy and clutter over time.
Architectural Evolution: An Unintended Catalyst for Discovery

Paradoxically, Buffer’s ability to uncover these long-lost processes was significantly aided by a prior, unrelated architectural shift. Like many technology companies, Buffer had embraced the microservices paradigm years ago. This approach involved breaking down a large, monolithic application into smaller, independent services, each with its own codebase, deployment pipeline, and dedicated infrastructure. The initial rationale was sound: microservices promised greater agility, independent scaling, and clearer boundaries between development teams.
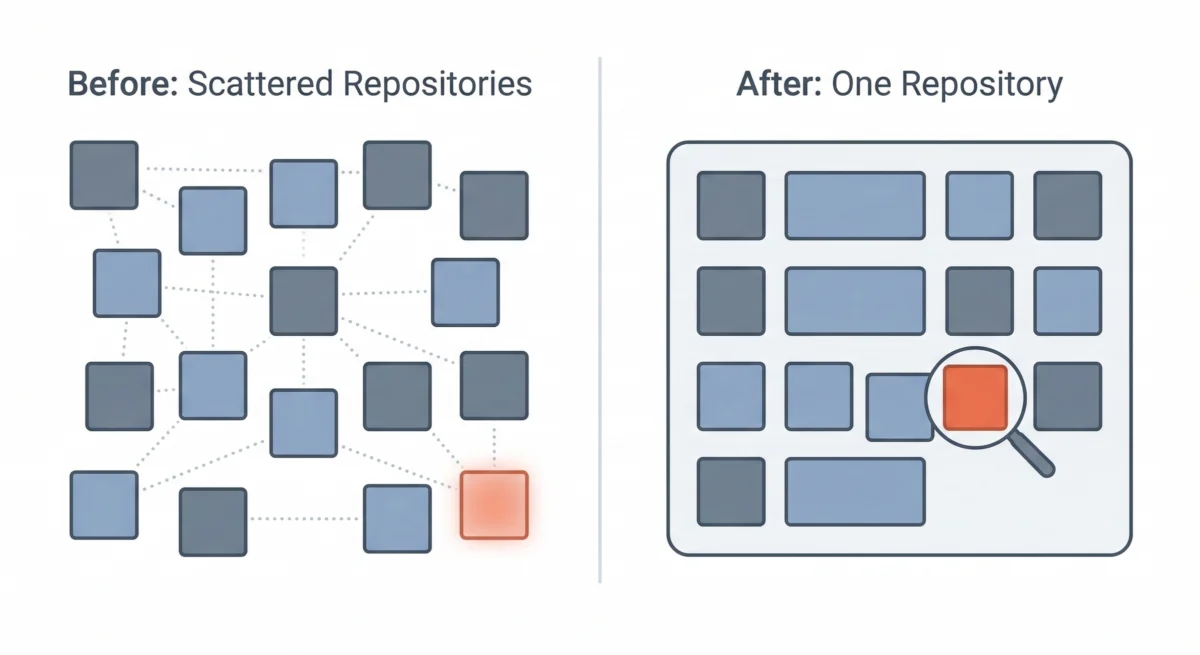
However, over time, Buffer found that for a team of its size, the overhead of managing dozens of separate repositories, each with its own CI/CD pipeline and operational concerns, began to outweigh the benefits. This led to a strategic decision to consolidate their architecture into a multi-service single repository, often referred to as a monorepo. While the logical boundaries between services remained intact, their codebases were co-located within a unified repository.
This consolidation proved to be the critical enabler for the recent discovery. In a fragmented microservices environment, a "forgotten" worker in one repository might exist in isolation, easily overlooked by engineers primarily focused on other services. There is no single, unified vantage point to search for queue names, trace message flows, or gain a holistic understanding of all running background tasks. Each service acts as its own "island," making cross-service visibility challenging.
With everything residing in a single repository, Buffer’s engineers gained an unprecedented panoramic view of their entire codebase. This unified perspective allowed them to:
- Trace Every Queue: Identify both the "producers" (systems sending messages) and "consumers" (systems receiving messages) for every SQS queue.
- Spot Discrepancies: Easily detect queues that had producers but no active consumers, or conversely, consumers referencing queues that no longer existed.
- Uncover Orphaned Workers: Pinpoint background processes or cron jobs that were attempting to interact with non-existent queues or performing operations without any downstream impact.
The move to a monorepo was not initially conceived as a strategy to combat technical debt or find "zombie" infrastructure. Its primary drivers were operational efficiency and developer experience. However, the enhanced visibility it provided made the discovery of these dormant processes not just possible, but almost inevitable. It underscored the serendipitous benefits that can arise from architectural simplification and consolidation.
A Methodical Approach to Remediation
Once the orphaned processes were identified, Buffer adopted a cautious and systematic approach to their removal, prioritizing system stability and minimizing risk. The remediation process unfolded in several distinct phases:
- Tracing Origin and Understanding Purpose: For each identified process, engineers embarked on a digital archaeological dig. They delved into git history, old documentation, and internal communication logs to uncover the original intent behind its creation. In most cases, the original purpose was eventually clarified: a one-time data migration, a feature that was subsequently sunsetted, or a temporary workaround that simply outlived its necessity.
- Rigorous Verification: Before any deletion, a critical step was to unequivocally confirm that the processes were indeed unused and not quietly fulfilling an obscure but vital function. This involved adding detailed logging to the suspect processes and monitoring their activity over several days. The goal was to ensure that no unexpected calls, data processing, or critical side effects were occurring. This cautious approach prevented accidental disruption to live systems.
- Incremental Removal: Rather than a wholesale deletion, the processes were removed one by one. This incremental approach allowed the engineering team to monitor for any unforeseen side effects or regressions after each removal. Fortunately, in this instance, no negative impacts were observed, reinforcing the initial assessment of their redundancy.
- Comprehensive Documentation: To prevent future engineers from wondering about "missing" components, thorough documentation was created. Internal notes detailed what each removed process had originally done, why it was created, and the rationale behind its decommissioning. This ensures that the institutional knowledge, once lost, is now preserved and accessible.
Immediate Impact and Future Prevention Strategies
The immediate benefits of this cleanup effort were evident. Buffer’s infrastructure inventory is now significantly more accurate, allowing engineers to confidently answer questions about active workers and system components. This improved clarity has also positively impacted the onboarding experience for new engineers, who no longer encounter perplexing, undocumented processes that necessitate time-consuming investigation. The codebase now more accurately reflects the company’s current operations rather than a historical record of past features and temporary fixes.
Looking forward, Buffer is committed to integrating these lessons into its ongoing development processes to prevent the recurrence of "zombie" infrastructure. The project has underscored a crucial takeaway: every significant refactor or system overhaul represents a valuable opportunity for "archaeology." When engineers are deeply immersed in understanding how system components connect, they are in the ideal position to question the necessity of every piece.
To embed these insights into their operational DNA, Buffer is implementing several preventative measures:
- Regular Audits: Instituting routine, perhaps quarterly, audits of SQS queues, cron jobs, and background workers to proactively identify and prune unused components.
- Mandatory Deprecation Protocols: Establishing formal processes for the deprecation and removal of features, ensuring that all associated infrastructure (queues, workers, storage, alerts) is explicitly accounted for and decommissioned.
- Automated Tooling and Monitoring: Exploring automated solutions for detecting orphaned resources or monitoring for prolonged periods of inactivity in specific background tasks, which could flag potential "zombies."
- Enhanced Documentation Standards: Reinforcing the importance of comprehensive and up-to-date documentation for all new services and background processes, including their purpose, dependencies, and lifecycle expectations.
Buffer acknowledges that older parts of its codebase still exist outside the consolidated repository, and as these are gradually migrated, the expectation is to uncover more hidden relics. However, with the new processes and the strategic benefits of their architectural consolidation, the company is now better equipped not only to discover existing dormant infrastructure but also to prevent new instances from emerging. The central lesson is clear: when all code lives in a unified environment, orphaned infrastructure has significantly fewer places to hide, paving the way for leaner, more efficient, and more understandable systems.