Buffer, the social media management platform, recently revealed the discovery of seven silently operating, non-functional background processes and workers within its system infrastructure, some of which had been running for up to five years. This unexpected find, uncovered during a routine system cleanup, highlights a pervasive challenge in software development: the accumulation of technical debt and "zombie" infrastructure that incurs costs, complicates operations, and erodes institutional knowledge.
The discovery originated from a seemingly modest project: an initiative to refine the internal communication mechanisms of Buffer’s systems. Specifically, engineers were tasked with updating local testing tools for Amazon Simple Queue Service (SQS) queues and streamlining their configurations. SQS queues function as critical asynchronous communication channels, allowing different parts of a system to exchange messages without direct, real-time interaction. One component can deposit a task message into a queue, and another can retrieve and process it at its convenience, enhancing system resilience and scalability.
However, as Buffer’s engineering team began mapping out the actual usage of their SQS queues, they stumbled upon an unanticipated revelation. Seven distinct background processes, including scheduled cron jobs and worker applications, were identified as having been continuously active for an extended period, in some cases spanning half a decade. Crucially, these processes were found to be performing no useful function whatsoever. The incident serves as a stark reminder of the often-hidden complexities and inefficiencies that can accumulate within long-lived software systems.
The Invisible Costs of Unseen Operations
While the immediate financial implications of these dormant processes were relatively modest, Buffer’s analysis suggests the true cost extends far beyond monetary waste. A quick calculation estimated that one of these workers alone would have accumulated operational costs of approximately $360-600 over its five-year lifespan. Extrapolated across multiple such processes, and considering the potential for similar undetected inefficiencies across larger organizations, the cumulative financial burden of "zombie" infrastructure can become substantial. Industry reports frequently highlight that a significant percentage of cloud computing budgets are wasted on underutilized or forgotten resources, underscoring the broader economic impact of such oversights.
Beyond the direct financial drain, the more insidious costs manifest in operational friction and a degradation of engineering efficacy. Each mysterious process encountered by a new team member necessitates time-consuming investigation. Questions like, "What does this worker do?" or "Is this critical?" consume valuable onboarding hours and foster an environment of uncertainty, where engineers may hesitate to modify or remove code for fear of disrupting an unknown, potentially vital, component. This ‘fear of touching’ is a classic symptom of high technical debt, hindering agility and increasing the cognitive load on development teams.
Furthermore, even dormant infrastructure demands attention. Security vulnerabilities in outdated dependencies, compatibility issues arising from system-wide upgrades, or routine maintenance for underlying platforms mean that engineering teams inadvertently dedicate resources to maintaining code paths that serve no operational purpose. This diverts focus from feature development, innovation, and genuinely critical maintenance, effectively creating a drag on team productivity. Over time, the institutional memory surrounding these components fades, making it increasingly difficult to ascertain their original intent or current necessity, especially as key personnel depart the organization.
The Genesis of Systemic Neglect: A Common Industry Challenge
The proliferation of these "zombie" processes is not attributed to individual failings but rather to systemic issues inherent in managing complex, evolving software architectures. It represents a natural consequence of entropy within long-lived systems, a phenomenon well-understood in the software engineering community.
Several common scenarios contribute to this problem:
- Feature Deprecation: A product feature is sunset, but the backend jobs or workers supporting it are not explicitly decommissioned.
- Temporary Solutions Becoming Permanent: A worker is spun up for a one-time data migration or a temporary workaround and subsequently forgotten, never being torn down.
- Architectural Shifts: Significant changes to system architecture render certain scheduled tasks or services redundant, but the corresponding infrastructure is not updated or removed.
Buffer’s own experience with a "birthday celebration" email service exemplifies this. Prior to 2020, the company ran a scheduled task that scanned its entire database daily to identify customer birthdays and dispatch personalized emails. During a transactional email tool refactor in 2020, the core functionality was migrated, but the original scheduled worker responsible for scanning and triggering these emails was inadvertently left running. For five additional years, this worker continued to execute its routine, consuming resources and contributing to system clutter, despite its output being entirely irrelevant. This incident underscores how easily even well-intentioned refactoring efforts can inadvertently leave behind orphaned processes without robust cleanup protocols.
Architectural Evolution: An Unexpected Aid in Discovery
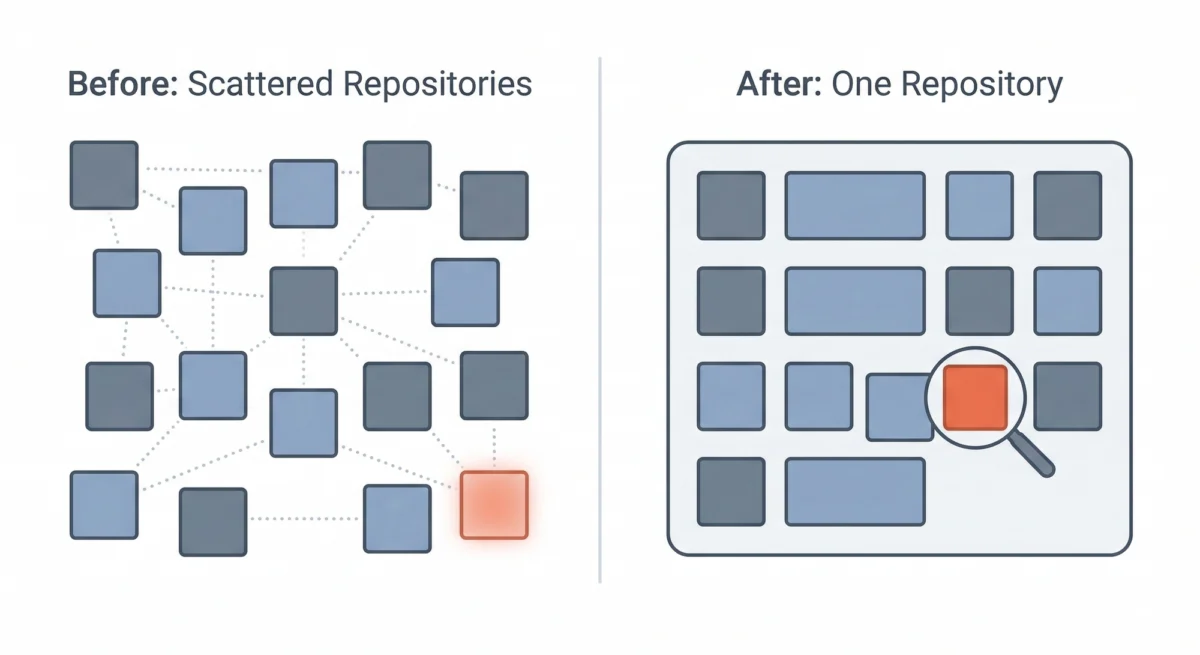
Ironically, the very architectural evolution that introduced complexity also provided the means for discovery. Like many technology companies, Buffer initially embraced the microservices paradigm years ago, segmenting its monolithic application into numerous small, independent services. Each microservice typically resided in its own code repository, with dedicated deployment pipelines and infrastructure. This approach promised benefits such as independent deployment, clear team boundaries, and enhanced scalability.

However, as the organization matured, Buffer recognized that for its specific team size and operational context, the overhead associated with managing dozens of disparate repositories began to outweigh the benefits. This led to a strategic consolidation, where services, while retaining their logical boundaries, were integrated into a multi-service single repository, often referred to as a monorepo.
This architectural shift, though not initially conceived as a tool for identifying dormant infrastructure, proved to be instrumental. In a fragmented microservices environment, a forgotten worker in one repository might remain unnoticed by engineers focused on another. The decentralized nature meant there was no single, unified view of all running processes, no central directory for queue names, and no easy way to trace dependencies across the entire system.
With the adoption of the monorepo, a holistic perspective became achievable. Engineers could now leverage unified tooling and a single codebase to trace every SQS queue to its consumers and producers. This centralized visibility allowed them to identify queues with producers but no active consumers, or workers referencing queues that had long ceased to exist. The consolidation, therefore, transformed the opaque landscape into a transparent one, making the discovery of orphaned infrastructure not just possible, but almost inevitable. This underscores a critical insight: architectural decisions, even when driven by other motivations, can have profound, unforeseen impacts on system discoverability and maintainability.
A Methodical Approach to Decommissioning
Upon identifying the orphaned processes, Buffer embarked on a systematic remediation strategy, emphasizing caution and thoroughness:
-
Tracing Origins: The first step involved an extensive forensic investigation. Engineers delved into Git history, internal documentation, and historical communication logs to understand the original rationale behind each worker’s creation. In most cases, the purpose became clear: a one-time data migration, a feature that was subsequently deprecated, or a temporary fix that outlived its utility. This historical context was crucial for making informed decisions about removal.
-
Confirming Inactivity: Before any process was decommissioned, a verification step was implemented. Logging mechanisms were enhanced to monitor the identified processes for a few days, ensuring they were genuinely inactive and not performing any subtle, overlooked functions. This cautious approach minimized the risk of unintended side effects or service disruptions.
-
Incremental Removal: Rather than a wholesale deletion, the processes were removed incrementally, one by one. This allowed the team to observe the system closely after each removal, watching for any unexpected behaviors or dependencies that might have been missed during the initial analysis. Fortunately, no adverse side effects were observed, validating the thoroughness of the preceding steps.
-
Documentation of Learnings: A critical final step involved documenting the entire process. Notes were added to Buffer’s internal knowledge base detailing the original purpose of each removed process and the rationale behind its decommissioning. This ensures that future engineers have access to this context, preventing a recurrence of the "missing context" problem and reinforcing institutional memory.
Beyond Cleanup: Cultivating a Culture of System Stewardship
The immediate benefits of this cleanup were tangible. Buffer’s infrastructure inventory is now accurate, enabling engineering teams to confidently answer questions about active workers and their functions. Onboarding for new engineers has been simplified, as they no longer encounter mysterious, non-functional components that create confusion and require additional explanation. The codebase now more accurately reflects the company’s current operational reality, rather than a historical artifact.
However, the long-term impact extends to a shift in engineering philosophy. Buffer’s experience underscores a vital lesson for the broader tech industry: every significant refactoring effort should be treated as an opportunity for "archaeology and prevention." When engineers are deeply engaged in understanding how system components interact, they are ideally positioned to scrutinize what remains essential and what has become obsolete. This perspective transforms refactoring from a purely optimization-driven task into a comprehensive system audit.
Moving forward, Buffer is integrating explicit cleanup protocols into its engineering processes:
- Dedicated Cleanup Phases: Allocating specific time and resources within refactoring projects to identify and decommission defunct infrastructure.
- Lifecycle Management: Implementing clearer lifecycle policies for services and background jobs, including explicit decommissioning plans when features are sunset or architectures evolve.
- Automated Auditing: Exploring tools and scripts that can periodically scan for anomalies, such as queues with no consumers or workers referencing non-existent resources.
- Centralized Visibility: Continuing to leverage the benefits of their consolidated repository to maintain a unified, transparent view of all system components.
Buffer still has older parts of its codebase yet to be migrated to the single repository. As this consolidation continues, the expectation is that more hidden relics of dormant infrastructure will be unearthed. However, the company is now better equipped, both architecturally and culturally, to catch these issues and prevent the accumulation of new ones. In an era of increasingly complex cloud-native architectures, Buffer’s experience serves as a compelling case study for the critical importance of proactive system stewardship, where orphaned infrastructure has nowhere to hide, fostering greater efficiency, clarity, and innovation.