The integration of artificial intelligence into creative workflows has rapidly shifted from niche experimentation to mainstream utility, fundamentally redefining how content creators approach visual asset generation. While initial skepticism often confined AI image generators to the realm of photorealism, a recent comprehensive evaluation demonstrates their profound potential in diverse applications, particularly for non-artists seeking bespoke visual elements. This analysis delves into the performance of nine prominent AI image generation models in 2026, revealing their strengths, limitations, and the nuanced art of effective prompt engineering, offering crucial insights for professionals navigating this dynamic technological frontier.

The Paradigm Shift in Visual Content Creation

Historically, many creators, especially those without traditional artistic training, found themselves limited by the time, skill, or budget required to produce unique illustrations or highly stylized graphics. The advent of sophisticated AI image generators has begun to bridge this gap, offering a powerful toolset that complements existing design platforms rather than merely replacing conventional photography. This shift marks a pivotal moment, democratizing access to high-quality visual content and empowering a broader spectrum of creators to realize their artistic visions. The global market for AI in media and entertainment, including image generation, is projected to reach tens of billions by the end of the decade, reflecting widespread adoption and continuous innovation.

Evolution of AI Image Generation: A Brief Chronology

The journey of AI image generation has been marked by rapid advancements and significant milestones:
- 2015-2017: Early generative adversarial networks (GANs) demonstrate basic image synthesis, often producing abstract or low-resolution outputs.
- 2019-2020: Advancements in transformer architectures begin to lay the groundwork for more coherent and diverse image generation.
- 2021: OpenAI’s DALL-E 1 captures global attention, showcasing the ability to generate images from text prompts, albeit with limitations.
- 2022: The release of DALL-E 2, Midjourney V1-V3, and the open-source Stable Diffusion democratizes access, leading to an explosion in user creativity and rapid community-driven development. These models significantly improve fidelity and stylistic range.
- 2023-2024: Companies like Adobe introduce Firefly, emphasizing ethical training data and commercial licensing. Models begin to integrate into existing creative suites, and specialized tools emerge for specific use cases like typography and graphic design. Ideogram and Seedream gain traction for their text-handling capabilities.
- 2025-2026: Iterations like Adobe Firefly 5, Ideogram 3.0, Nano Banana 2, and FLUX.2 Pro push boundaries in accuracy, stylistic control, and integration, demonstrating continuous refinement in understanding complex prompts and rendering intricate details. The focus shifts towards practical application in commercial content creation.
Mastering the Art of Prompt Engineering

The bottleneck in AI image generation has increasingly shifted from the technology itself to the user’s ability to articulate their vision. Effective prompt engineering, a burgeoning skill, is crucial for unlocking the full potential of these sophisticated algorithms. A recent evaluation of nine leading models revealed consistent principles that yield superior results:

- Subject-First Prioritization: Consistently, models respond more effectively when the prompt begins with a clear description of the subject and its actions, followed by stylistic descriptors. For instance, "A woman sitting at a desk with a laptop open" precedes "editorial lifestyle photography, warm natural light." Reversing this order often leads to aesthetically pleasing but content-vague outputs, indicating the model prioritizes style over specific elements.
- Leveraging Camera Terminology for Photorealism: Achieving photorealistic results hinges on employing precise photography jargon. Terms such as "shallow depth of field," "shot from a slight angle," "soft golden hour lighting," and "35mm film photography" resonate strongly with models trained on vast datasets of image captions and photography metadata. Generic terms like "beautiful" or "high quality" prove largely ineffectual.
- Descriptive Color Language: While some design-centric tools like Recraft can interpret hex codes, plain language descriptions ("light blue," "butter yellow") consistently produced more accurate color representations across the majority of tested models. For brand-specific accuracy, experimentation with both methods is recommended, especially in tools designed for graphic designers.
- Anchoring Illustration Styles: Unlike photorealism, where models have a robust understanding of visual cues, generating specific illustration styles requires explicit guidance. Prompts must detail the type of illustration, medium, and technique. Examples include "hand-drawn doodle, light blue ink, single color, simple line art with slightly wobbly quality, outlines only," or more granular terms like "ink hatching, gouache blocks, flat vector shapes, stipple shading, gestural linework." Without such specificity, models often default to generic, often dated, clip-art aesthetics.
- Strategic Use of Negative Prompts: Underrated but powerful, negative prompts ("no watermark," "no text," "no photorealism") significantly refine outputs by excluding undesirable elements. Their efficacy, however, is contingent on an already robust core prompt; they serve as a refinement mechanism, not a foundational corrective. Placing critical exclusions early in the negative prompt string maximizes their impact.
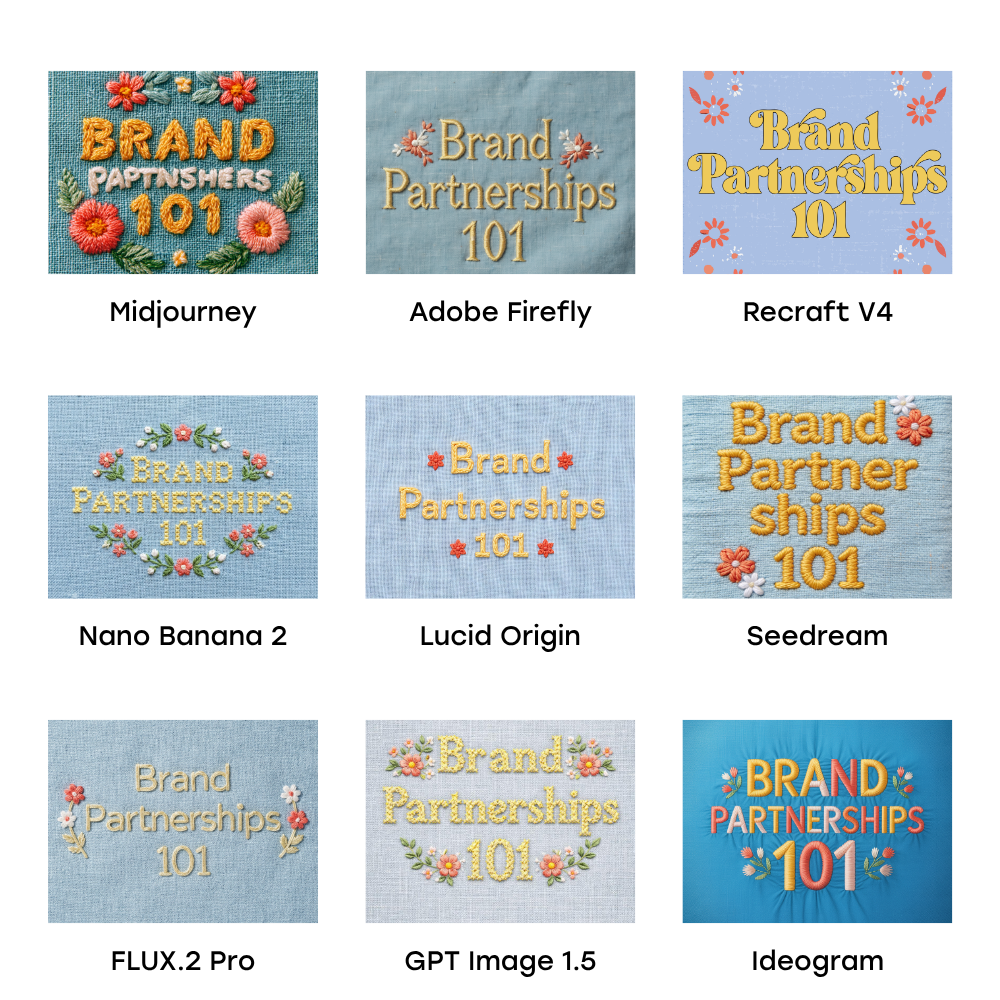
Based on these principles, a consistent prompt structure emerged: [Subject and what they’re doing] + [setting or context] + [2 or more specific details] + [style]. This framework proved effective across diverse stylistic requirements, from intricate sticker sheets to styled product photography and embroidered typography.

Comparative Analysis of Leading AI Image Generators (2026)

Nine leading AI image generation models were rigorously tested against three distinct prompts: a hand-drawn doodle sticker sheet, a styled product flat lay, and an embroidered typography graphic. The models were evaluated for their adherence to prompt details, aesthetic quality, and specialized capabilities. For broader accessibility, several models were tested within the Leonardo.ai platform, chosen for its multi-model access and Canva integration, while Midjourney, Recraft, and Adobe Firefly were assessed as standalone applications.

Key Takeaways from the Evaluation:
- Nano Banana 2 (Google): Emerged as the most consistently accurate performer across all three test categories. Its apparent ability to draw from extensive indexed visual data (e.g., Google Search, Google Shopping) allowed it to render specific real-world objects and brands with remarkable fidelity, particularly in illustration.
- Seedream (ByteDance): Demonstrated exceptional reliability in generating accurate text within images, a common stumbling block for many models. Its integration with CapCut Pro adds value for creators in that ecosystem.
- Recraft V4 Pro: While sometimes taking creative liberties, Recraft produced some of the most artistically rich and visually cohesive outputs. Its extensive reference library and agentic chat features offer unparalleled control for designers seeking specific aesthetic directions.
- Midjourney: Maintained its reputation for artistic, mood-driven visuals, excelling in overall composition and atmospheric rendering. However, it consistently struggled with precise object specificity and accurate text generation.
- Adobe Firefly 5: Stood out for its seamless integration into the Adobe Creative Cloud ecosystem and its transparent, ethically sourced training data, offering clearer commercial licensing. It exhibited strong performance in photorealism and typography, albeit with a cautious approach to brand-name recognition in prompts.
Individual Model Performance in Detail:

-
Midjourney: While visually rich and strong on overall composition, it faltered on granular details. The sticker sheet prompt, requiring 13 specific objects, proved challenging, with many items being approximated or omitted. Photorealism exhibited strong lighting and mood but blurred critical details like product screens and specific branding. Typography was a significant weakness, often garbling words despite excellent texture rendering.

- Implication: Best suited for conceptual art, mood boards, and abstract visuals where precise object rendering and text accuracy are secondary.
-
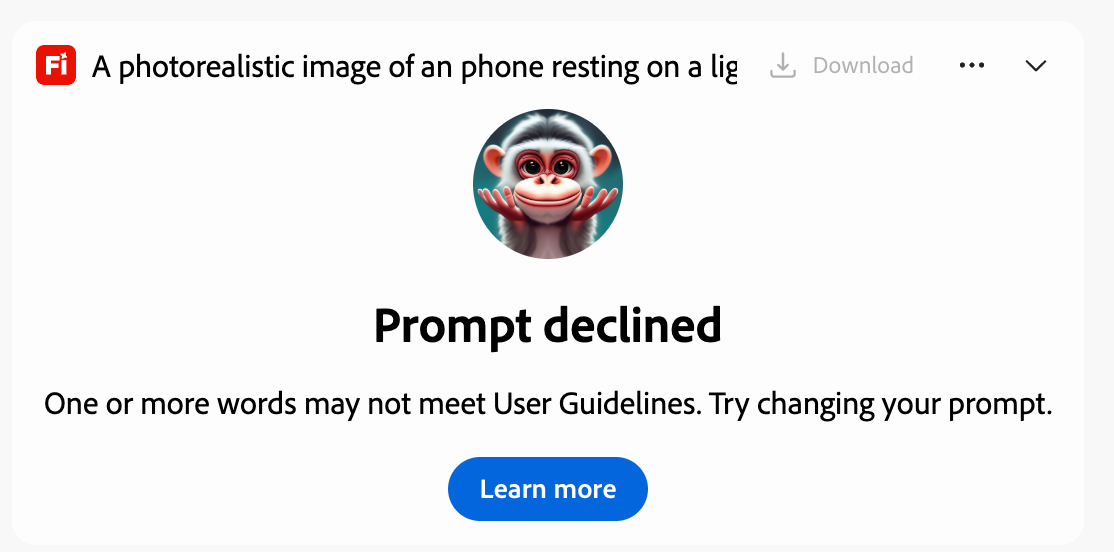
Adobe Firefly 5: A strong contender for creators embedded in the Adobe ecosystem. Its "whimsical" hand-drawn illustrations were aesthetically pleasing but showed minor inaccuracies in object details. The model’s copyright-conscious training was evident in its refusal of brand names like "iPhone" and "Instagram" in prompts, a critical consideration for commercial users. Typography results were strong, with realistic fabric textures and legible text.

- Implication: Ideal for enterprise users prioritizing clear commercial rights and seamless workflow integration, provided they adapt to brand-name restrictions.
-
Recraft V4 Pro: Excelled in offering stylistic control and an impressive library of design references. Its Vector Pro model delivered a genuine hand-drawn quality in illustrations, though inconsistencies in color and object specificity were noted without further refinement. Photorealism was initially convincing but broke down on close inspection of details like phone dimensions and on-screen content. Recraft’s typography often veered creatively from the prompt but produced aesthetically compelling, handcrafted results.

- Implication: A powerful tool for designers and creators demanding high stylistic control and willing to leverage its advanced refinement features.
-
GPT Image 1.5 (OpenAI): Tested via Leonardo.ai, this model offered a glimpse into the underlying technology powering ChatGPT’s image capabilities. Illustrations suffered from a compressed look and a pervasive yellowish tint, often struggling with empty space. Photorealism came closer but missed critical branding cues on screens. Typography was technically accurate in its cross-stitch rendition but lacked aesthetic appeal for commercial use.

- Implication: Convenient for existing ChatGPT users for quick, simple image generation, but requires more precise prompting and refinement for high-quality outputs.
-
Nano Banana 2 (Google): The standout performer. Its illustration outputs were highly accurate, capturing specific object styles (e.g., Diptyque Orphéon bottle, Salomon sneakers) and rendering magazine spines with believable fonts. Photorealism was impressive, even spontaneously adding contextual elements (notebook, earbuds) that enhanced realism. Typography was whimsical, stylized, and cohesive, making it a preferred output.

- Implication: Highly recommended for creators needing precise rendering of specific real-world objects and styles, especially for detailed illustration work.
-
Seedream (ByteDance): Produced the most "sticker-like" effect in illustrations but with some object inaccuracies (unrequested phone on magazines, transparent headphones). Its strength lay in text generation, delivering spot-on spelling and labels. Photorealism had a weak phone rendering but strong surrounding elements. Typography was largely accurate, with realistic fabric texture, though the font weight felt slightly cartoonish.

- Implication: A strong choice for creators prioritizing accurate text generation and integrated with the CapCut ecosystem, despite minor object inaccuracies.
-
Ideogram 3.0: Positioned for text generation, it achieved about 75% accuracy in this evaluation. Illustration colors were off, and the style was generic, often misinterpreting specific plant requests. Photorealism suffered from an "uncanny valley" effect, appearing almost real but clearly artificial on closer inspection. Typography adopted a cartoonish embroidery style that lacked the desired handcrafted realism.

- Implication: Useful for text-focused graphics, but requires significant prompt refinement or reference images to achieve specific visual styles and object accuracy.
-
FLUX.2 Pro: Exhibited a creative interpretation of prompts. For illustration, it generated physically laid-out, printed stickers rather than flat digital illustrations, showcasing a unique dimensional quality. Photorealism was decent, with good shadows and unexpected branding on the coffee cup, but the phone still lacked realism. Its embroidery texture was impressive, but the text appeared "glued on" rather than integrated.

- Implication: Suited for creators seeking models that offer unexpected, artistic interpretations and a distinct visual point of view, accepting less predictable outcomes.
-
Lucid Origin: Offered fast generation with a distinctive dimensional quality. Illustrations had an "embossed" effect but struggled with text and object accuracy. Photorealism uniquely interpreted "flat lay" as a true top-down shot but delivered unrealistic ice and screen content. Typography had a raised, stylistic quality, appealing for an "inspired by embroidery" look rather than strict realism.

- Implication: Good for quick generation of visuals with a unique dimensional aesthetic, provided pixel-perfect prompt adherence is not the primary concern.
Underlying Technologies: Diffusion vs. Autoregressive Models

The disparate performance across models often stems from their underlying architectural differences.
- Diffusion Models (e.g., FLUX, Stable Diffusion, Midjourney) operate by starting with random noise and iteratively refining it into an image based on the prompt. This "denoising" process often results in highly artistic, textured, and cohesive images, as the model builds the entire visual simultaneously.
- Autoregressive Models (e.g., Google’s Imagen/Nano Banana 2, OpenAI’s GPT Image) generate images sequentially, pixel by pixel or token by token, akin to constructing a sentence. This step-by-step approach tends to be better at following complex, detailed instructions and maintaining object specificity, as seen with Nano Banana 2’s performance.
While the lines blur with hybrid architectures, understanding these fundamental approaches helps explain why certain models excel in specific tasks—diffusion models often for artistic flair, autoregressive for detailed adherence. These models learn from vast datasets of images and their corresponding text descriptions, which is why precise vocabulary, whether photographic or illustrative, yields superior results.

Broader Implications: Intellectual Property, Ethics, and the Future

The rapid evolution of AI image generation carries significant implications for various stakeholders:
- Intellectual Property and Copyright: The U.S. Copyright Office’s stance that purely AI-generated images are not copyrightable, upheld by the Supreme Court in March 2026, creates a complex legal landscape. While commercial use is generally permitted by tool providers, creators cannot claim exclusive ownership of raw AI outputs. This necessitates further modification and integration into original human-authored works to strengthen IP claims. Adobe Firefly’s proactive approach to IP indemnification, based on its licensed training data, represents a key differentiator for corporate users seeking legal certainty. The outcome of over 70 ongoing copyright lawsuits, particularly the landmark case against Stability AI and Midjourney going to trial in September 2026, will significantly shape future IP frameworks.
- Ethical Considerations: The use of vast, often unattributed, internet datasets for training raises ethical questions about fair compensation for artists whose work implicitly contributes to AI models. The ability to generate convincing images of non-existent people, or even resemblances of real individuals, presents right-of-publicity risks and deeper ethical dilemmas regarding authenticity and potential misuse. Responsible development and clear disclosure of AI-generated content remain paramount.
- Impact on Creative Industries: AI image generators are not universally seen as replacements for human artists but rather as powerful augmentative tools. They can accelerate ideation, create diverse stylistic variations, and enable non-specialists to produce compelling visuals. This could lead to a redefinition of creative roles, with an increased demand for prompt engineers, AI-assisted designers, and artists who leverage AI as a creative partner. Marketing, advertising, and content creation industries are already experiencing increased efficiency and personalization capabilities.
- Accessibility and Cost: Most leading AI image generators offer free tiers or trial credits, democratizing access to powerful creative tools. Platforms like Leonardo.ai provide a cost-effective entry point to experiment with multiple models. This low barrier to entry fosters innovation and expands the pool of visual content creators.
Conclusion: A Powerful Toolkit for the Modern Creator

The 2026 landscape of AI image generators is sophisticated and diverse, offering specialized tools for nearly every creative need. Nano Banana 2 stands out for its accuracy and detailed rendering, particularly in illustrations, while Seedream excels in text generation. For artistic flair and advanced control, Recraft and Midjourney remain top choices, though with caveats regarding precision. Adobe Firefly carves a niche with its ethical data sourcing and seamless integration.

The evaluation underscores that the effectiveness of these tools is directly proportional to the user’s proficiency in prompt engineering. As AI models continue to advance, the distinction between "obviously AI" and human-created visuals is rapidly blurring, particularly in stylized graphics. While photorealism still presents challenges in minute details, the overall quality and utility of AI-generated images for content creation are undeniable. For creators and businesses, embracing these tools, understanding their nuances, and navigating the evolving ethical and legal frameworks will be crucial for success in the digital age. The future of visual content is increasingly a collaborative endeavor between human ingenuity and artificial intelligence.