San Francisco, CA – In a revealing internal audit, Buffer, the popular social media management platform, has unearthed a significant amount of "zombie infrastructure"—seven background processes and workers that had been running silently and purposelessly for up to five years. The discovery, made during a routine system cleanup, sheds light on the often-overlooked costs of technical debt, not just in financial terms, but in operational efficiency, engineering morale, and the erosion of institutional knowledge within long-lived software systems. The incident underscores the critical importance of proactive system hygiene and the unexpected benefits that can emerge from architectural shifts.
The genesis of this discovery was a seemingly modest project: a thorough cleanup of Buffer’s internal communication mechanisms, specifically focusing on its use of Amazon Simple Queue Service (SQS). SQS queues are a foundational component in modern distributed systems, acting as asynchronous messaging services where one part of a system can deposit a "message" or task, and another part can retrieve and process it later. This decoupled communication allows systems to scale more efficiently, as the sender doesn’t need to wait for the receiver to be immediately available. Buffer utilizes these queues extensively, alongside cron jobs (scheduled tasks that run automatically), to manage a myriad of backend operations, from data processing to user notifications. The initial goal was straightforward: update local testing tools for these queues and streamline their configuration.
However, as engineers began mapping out the active queues and their associated processes, they stumbled upon an unexpected anomaly. What began as routine maintenance quickly evolved into an archaeological dig, unearthing seven distinct background processes and workers that were actively consuming resources but performing no valuable function whatsoever. These silent, defunct operations had been embedded within Buffer’s systems for as long as half a decade, a testament to the insidious nature of system entropy.
The Hidden Toll: Beyond Monetary Waste
While the immediate reaction might be to quantify the financial loss, Buffer’s analysis reveals that the monetary cost, though real, is merely the tip of the iceberg. A quick calculation estimated that a single one of these dormant workers could have cost the company approximately $360 to $600 over its five-year lifespan. Extrapolating this modest figure across seven such processes suggests a cumulative waste potentially exceeding $4,000 – an amount that, while not catastrophic for a company of Buffer’s scale, represents pure, unadulterated expenditure on nothing. This figure also doesn’t account for any ancillary resources these processes might have consumed, such as database connections, network bandwidth, or even subtle impacts on other system performance metrics.
However, the deeper implications extend far beyond the balance sheet. The presence of these "ghost processes" incurred significant, often invisible, costs related to:
- Cognitive Load and Onboarding Inefficiency: Every new engineer joining the Buffer team would inevitably encounter these mysterious processes. Questions like "What does this worker do?" or "Is this still active?" would arise, leading to wasted time investigating defunct code paths. This creates uncertainty, slows down the onboarding process, and diverts valuable time from productive work. Engineers are often hesitant to remove or modify code they don’t fully understand, fearing unforeseen consequences, perpetuating the problem.
- Maintenance Overhead: Even dormant infrastructure demands attention. Security vulnerabilities in outdated dependencies, necessary library updates, or compatibility fixes when other system components evolve can necessitate maintenance cycles on code that serves no actual purpose. This diverts engineering resources away from developing new features or improving existing ones, contributing to a growing "technical debt" burden.
- Erosion of Institutional Knowledge: Over time, the original context and purpose behind these processes fade. The engineers who initially created them might have moved on, taking with them the critical historical understanding. This loss of institutional memory makes it increasingly difficult to assess the necessity of legacy components, often leading to a conservative "don’t touch it if it’s not broken" mentality that allows dead code to persist indefinitely.
The Genesis of "Zombie" Infrastructure: A Natural Phenomenon
The existence of such dormant infrastructure is not unique to Buffer and is, in fact, a common byproduct of evolving software systems. It’s rarely the result of individual negligence but rather a systemic failure of process, as the Buffer team candidly acknowledged. Several common scenarios contribute to this accumulation:
- Feature Deprecation: When a product feature is retired, the underlying background jobs or workers that supported it are sometimes overlooked and left running.
- Temporary Solutions Becoming Permanent: Engineers might spin up a worker "temporarily" to handle a one-time data migration or a short-term workaround. Without a robust decommissioning plan, these temporary solutions can easily become permanent fixtures.
- Architectural Shifts: Major refactoring or architectural changes can render certain scheduled tasks or processes redundant. If the interconnectedness isn’t thoroughly mapped, these older components can continue to operate in the background, unaware of their new irrelevance.
A vivid example from Buffer’s history illustrates this point: the "birthday celebration email" worker. For years, Buffer celebrated its users’ birthdays by sending personalized emails. This was managed by a scheduled task that scanned the entire database daily for matching birthdays. In 2020, as part of a significant refactor, Buffer switched its transactional email tool. While the new system handled all active email communications, the old birthday email worker was simply forgotten. It continued to execute its daily scan for five more years, performing its checks and attempting to send emails via a now-defunct pathway, consuming resources without delivering a single message. This incident perfectly encapsulates how a lack of intentional cleanup processes allows entropy to win, silently accumulating technical debt.
Architectural Evolution: The Key to Discovery
Ironically, the very architectural decisions Buffer made years ago, first contributing to the problem, ultimately provided the solution for its discovery. Like many tech companies seeking scalability and agility, Buffer embraced the microservices architecture paradigm years ago. This approach advocates for breaking down a large, monolithic application into smaller, independent services, each with its own codebase (repository), deployment pipeline, and dedicated infrastructure. The initial appeal was clear: enhanced autonomy for teams, faster deployments, and clearer boundaries between different parts of the system.
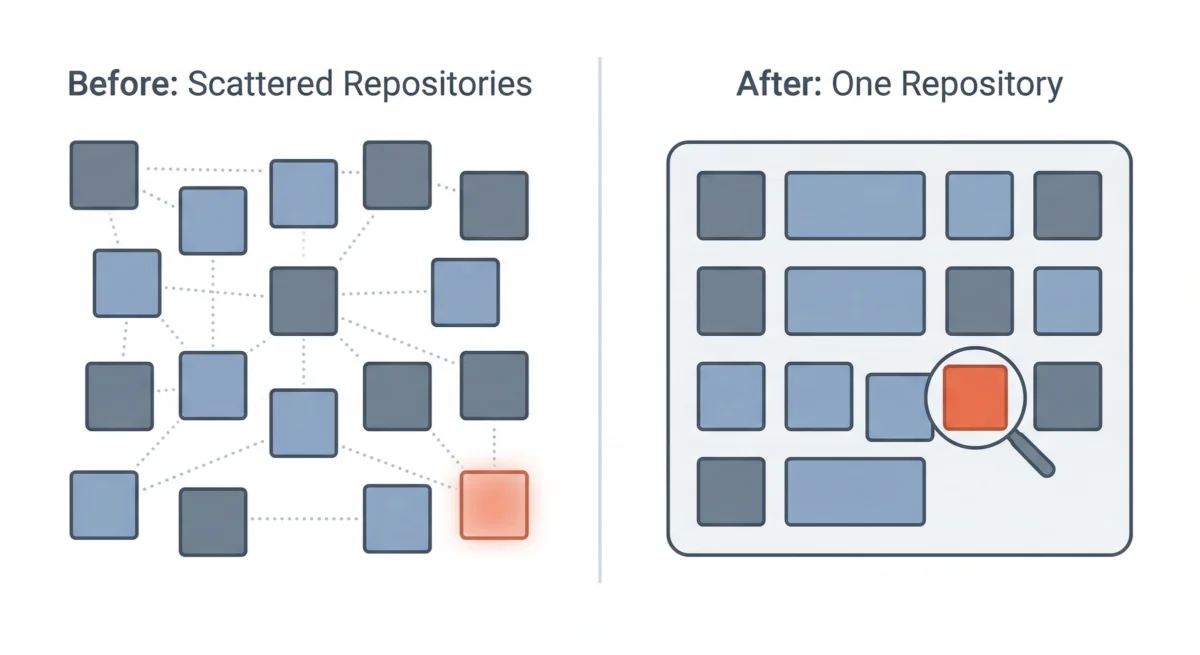
However, over time, Buffer, like other organizations, began to experience some of the drawbacks associated with a purely decentralized microservices model, particularly for a team of its size. The overhead of managing dozens of separate repositories, each with its own CI/CD setup and operational nuances, started to outweigh the perceived benefits. This led to a strategic pivot: the consolidation into a multi-service single repository, often referred to as a monorepo. While the services still maintain their logical boundaries and distinct responsibilities, their codebases now reside together in one unified location.

This architectural shift proved to be an unexpected boon for discovering the zombie infrastructure. In a fragmented microservices environment, each service’s repository often acts as an isolated island. A forgotten worker within one repository might easily escape the notice of engineers primarily focused on another service. There is no single, centralized vantage point to search for queue names, identify orphaned processes, or gain a comprehensive understanding of all background tasks running across the entire ecosystem.
The consolidation changed everything. With all code residing in a single repository, Buffer’s engineers gained an unprecedented holistic view of their system. They could now:
- Trace End-to-End: Follow the path of every message queue from its producers (where messages are sent) to its consumers (where messages are processed).
- Identify Orphans: Easily spot queues that had producers sending messages but no active consumers picking them up, indicating a broken or defunct process.
- Detect Redundancies: Locate workers that referenced queues or other system components that no longer existed, signifying their own obsolescence.
The multi-service single repository, while not initially designed as a technical debt clean-up tool, serendipitously created the transparency needed to make the discovery of these silent, useless processes almost inevitable. It provided the necessary "single pane of glass" to conduct a thorough audit.
A Methodical Approach to Decommissioning
Once the orphaned processes were identified, Buffer adopted a meticulous, multi-step approach to their decommissioning:
- Origin Tracing: For each identified process, engineers delved into its history, examining Git commit logs, internal documentation, and even old communication channels to understand its original purpose. This archaeological phase helped confirm whether the process was indeed a temporary fix, a deprecated feature remnant, or a one-time migration worker that had overstayed its welcome.
- Verification of Disuse: Before any process was removed, a crucial verification step was implemented. Logging was added to the suspected defunct processes, and they were monitored for several days. This was to ensure that no hidden, critical function was being performed that had been missed during the initial analysis. This cautious approach prevented any unintended disruptions to the live system.
- Incremental Removal: To mitigate risk, the identified processes were not deleted en masse. Instead, they were removed one by one, with close monitoring after each removal for any unexpected side effects or system instabilities. Fortunately, the methodical approach confirmed that the processes were indeed dormant, and no adverse impacts were observed.
- Comprehensive Documentation: To prevent future confusion and preserve institutional knowledge, thorough notes were added to Buffer’s internal documentation. These notes detailed what each process originally did, why it was created, and the rationale behind its removal. This ensures that future engineers will not waste time investigating "missing" components or inadvertently reintroducing defunct code.
The Immediate and Future Impact
The cleanup project, while still in its early stages of full impact measurement, has already yielded tangible benefits for Buffer. The most immediate outcome is a significantly more accurate and reliable infrastructure inventory. When asked about the active workers or background processes, the engineering team can now provide confident, up-to-date answers, eliminating guesswork and fostering a clearer understanding of the operational landscape.
Furthermore, onboarding conversations for new engineers have become markedly simpler. New hires are no longer sidetracked by mysterious, defunct processes, allowing them to focus on understanding the truly active and relevant parts of the codebase. The codebase itself now more accurately reflects the current state of Buffer’s operations, rather than a historical accumulation of past projects and temporary solutions.
The biggest takeaway from this entire endeavor, as articulated by the Buffer team, is to treat every significant refactoring effort as an opportunity for "archaeology" and proactive prevention. When engineers are deeply engaged in understanding how system components connect and interact, they are in the prime position to question the necessity of every piece. That queue from a forgotten project, the worker created for a one-time data migration, or the scheduled task referencing an unfamiliar feature – these are all potential candidates for decommissioning.
Moving forward, Buffer is integrating these lessons into its core engineering processes:
- Structured Deprecation: Building explicit cleanup steps into the workflow for feature deprecation, ensuring that all associated infrastructure is retired alongside the feature.
- Regular Audits: Implementing scheduled, periodic audits of background jobs and queue consumers to proactively identify and address dormant processes.
- Sunset Clauses for Temporary Solutions: Requiring clear sunset dates and decommissioning plans for any temporary workers or scripts spun up for migrations or short-term needs.
As Buffer continues its architectural consolidation, migrating older parts of its codebase into the single repository, the expectation is that more hidden relics will be uncovered. However, the company is now better equipped not only to find these remnants but also to establish robust processes that prevent new "zombie" infrastructure from forming. The overarching lesson is clear: in a unified and transparent codebase, orphaned infrastructure truly has nowhere to hide, paving the way for a more efficient, understandable, and sustainable engineering ecosystem.